In my
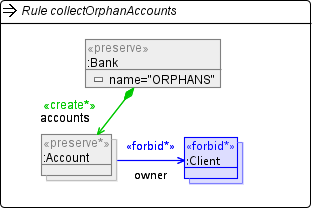
last post, I reported on an improvement of the graph pattern matching algorithm in Henshin that showed a major performance boost for rules where the nodes in the left-hand sides are connected only by <<require>> nodes and edges. As a concrete example, we used the transformation rule below to find couples of actors / actresses in the IMDB movie database which starred together in at least three movies.
Thanks to the tweak in the pattern matching engine we were able to apply this rule to much larger input graphs. Unfortunately, the synthetic test data that we used for our last benchmark does not have the same complexity as the real data from IMDB. In our test data, every person played in not more than 10 movies and every movie had a similarly low number of actors / actresses. In reality, the IMDB data contains movies with more than 1000 actors and obviously also persons that played in a large number of movies.
So I executed our find-couples example on the real IMDB data (thanks for the data import, Tassilo!). Not surprisingly, the results were much worse than for the synthetic data. The reason for this is that the real IMDB data is much more interconnected. So I started tweaking the pattern matcher of Henshin again. Eventually, I realized that I need something more to crack this nut.
 |
| SAP Coding Masters 2013 |
A possible way to improve the performance is to parallelize the graph pattern matching algorithm. In the current development version of Henshin, this is actually implemented! Here is how you can enable it:
int partitions = 10;
EGraph graph = new PartitionedEGraphImpl(model,partitions);
Engine engine = new EngineImpl();
engine.getOptines.put(Engine.OPTION_WORKER_THREADS,
partitions);
// Execute transformation
engine.shutdown();
You need to use the new implementation of
EGraph called
PartitionedEGraphImpl. It basically splits up the graph to be transformed into
N disjoint partitions. The second change you need to do is to set the number of worker threads in the transformation engine. In theory, this number can be different to the number of partitions, but the easiest setup is to just use the same amount of threads as there are partitions. The third point you need to ensure is that your rule uses *-stereotypes for nodes and edges (essentially it transforms all matches at once). Finally, you should shutdown the engine when your done to get rid of the worker threads.
For the example of finding couples in the IMDB database, this parallel graph pattern matching approach works actually quite well. Below you can see the performance gains achieved on an ordinary desktop computer.
With this new parallel graph pattern matcher in the interpreter, and the recently introduced Giraph code generator, Henshin really is becoming a big-data tool, which I find very exciting.
Update (07 February 2014)
I realized that the performance in absolute number is still quite bad. As I wrote in my earlier post, the optimized match finder uses path constraints to check the existence of the movies which connect the actors. The problem was though that the match finder still made an additional check whether the <<require>> elements exist, i.e., it performed a complete matching of the PAC (positive application condition). This is actually not necessary here because the path constraint is sufficient already.
To fix this problem, I added a static analysis which finds out once in the beginning whether path constraints are enough to check the PAC. This significantly reduces the run-times as you can see below. Using 12 worker threads, the processing of 2 million nodes takes 173 seconds. But to be honest, I have my doubts whether these engine optimizations will be helpful also in other cases.
| Nodes |
Couples |
Time (ms) |
| 499,995 |
79,470 |
6,582 |
| 1,004,463 |
244,627 |
27,239 |
| 1,505,143 |
585,689 |
87,721 |
| 2,000,900 |
1,017,752 |
173,142 |